1. Introduction to LLLPG
30 May 2016 (although LLLPG 0.9 was first published 7 Oct 2013)LLLPG (Loyc LL(k) Parser Generator) is a recursive-decent parser generator for C#, with a feature set slightly better than ANTLR version 2. It’s a system that I decided to create after trying to use ANTLR3’s C# module - about seven years ago now - and ran into C#-specific bugs that I couldn’t overcome. The author of ANTLR, a Java guy, wasn’t about to fix them, and the author of the C# target had seemingly vanished.
Besides, I wasn’t happy with the ANTLR-generated code; I thought I could generate simpler and more efficient code. “How hard could it be to make an LL(k) parser generator?” I wondered. The answer: really hard, actually. Even today I’ve never seen a paper about how it should be done. Since I didn’t really know what I was doing, it ended up taking several years to write LLLPG, and while its performance could use improvement, I’m happy with the result.
While ANTLR has advanced some ways in that time period, it is still Java-centric, and I think the advantages of LLLPG still make it worth considering even if all the major C#-specific bugs in ANTLR have been fixed (I don’t know if they have or not, but the C# version still lags behind the Java version).
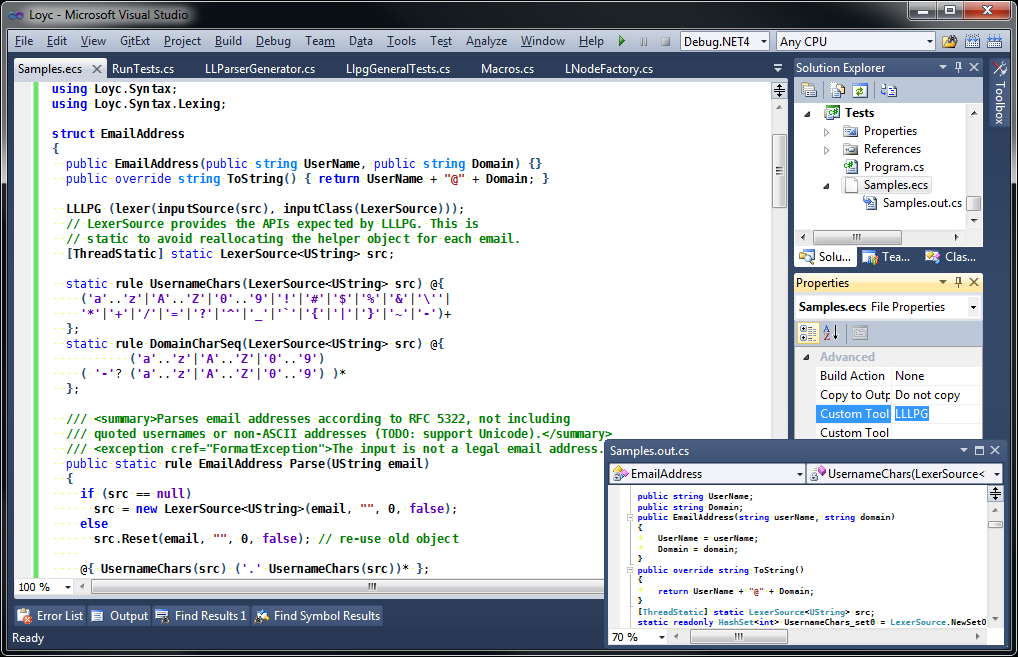
Typically, you will use the LLLPG Visual Studio Custom Tool (a.k.a. Single-File Generator):
What kind of parser generator is LLLPG?
There are several types of parser generators, e.g. LALR(1), PEG, LL(1), LL(k), and LL(*). Of these, I think PEG (Parsing Expression Grammars, usually implemented with packrat parsers) and LL(k)/LL(*) (hand-written parsers and ANTLR 3/4) are the most popular for writing new grammars today (some people also use regular expressions, but regexes are much less powerful than “proper” parser generators because they do not support full recursion).
Of course, LLLPG is an LL(k) parser generator. In addition to plain LL(k), LLLPG has a few extra, advanced features because some programming languages are difficult to express with an LL(k) grammar alone. LL(k) has two main advantages: potentially high performance (especially if k is low), and output that is relatively easy to understand. To be honest, ANTLR 3/4 is more powerful than LLLPG because the lookahead value k is unlimited, but unlimited lookahead is not free; if your goal is to write a fast parser, limiting yourself to LL(k) is something you might do anyway. In LLLPG, you can still do unlimited lookahead with a zero-width assertion, it’s just not automatic; you have to ask for it.
LLLPG is not a dedicated tool the way ANTLR is. Instead, LLLPG is designed to be embedded inside another programming language. While you may use LLLPG similarly to other parser generators, it’s really just a “macro” inside a programming language I’m making called Enhanced C# — one of a hundred macros that you might be using, and perhaps in the future you’ll write a macro or two yourself.
As of early 2016, Enhanced C# is incomplete; only two components of it are ready (the parser, and the macro runner which is called LeMP). Hopefully though, you’ll find it fairly user-friendly and fun.
A focus on prediction
LLLPG is designed to focus on one job and do it as well as possible: LL(k) prediction analysis. LLLPG doesn’t try to do everything for you: it doesn’t construct tokens, it doesn’t create syntax trees. You’re a programmer, and you already have a programming language; so I assume you know enough to design your own Token class and syntax tree classes. If I designed and built your syntax trees for you, I figure I’d just be increasing the learning curve: not only would you have to learn how to use LLLPG, you’d have to learn my class library too! No, LLLPG’s main goal is to eliminate the most difficult and error-prone part of writing LL(k) parsers by hand: figuring out which branch to take, or which method to call. LLLPG still leaves you in charge of the rest.
That said, I have designed a universal syntax tree as part of the Loyc project, called the Loyc tree, but LLLPG is not oriented toward helping you use them. Even so, I hope you’ll consider using Loyc trees, and this manual will show you how later. Internally, LLLPG uses them heavily.
Advantages of LLLPG over other tools
- LLLPG generates simple, relatively concise code, similar to what you would write by hand (it is more verbose, but not bad). I haven’t tried ANTLR 4, but LLLPG usually produces simpler output than ANTLR 3.
- Speed over beauty: LLLPG tries to produce code that is easy-to-follow, but it selectively uses
gotoandswitchstatements to maximize performance. It does not use exceptions for backtracking; actually, it doesn’t do backtracking at all except when you use syntactic predicates, which create special backtracking subparsers called “recognizers”. - As a Visual Studio Custom Tool, it is ideal for medium-size parsing tasks that are a bit too large for a regex. LLLPG is also sophisticated enough to parse complex languages like “Enhanced C#”, LLLPG’s usual input language.
- You can add a parser to an existing class–ideal for writing
static Parsemethods. - You can avoid memory allocation during parsing (ideal for parsing short strings!)
- LLLPG is designed to not need a runtime library; it can get by with just a single base class (actually two in practice, one for lexers and one for parsers) that you can copy from me (or rewrite yourself, if you enjoy easy work). However, I suggest using Loyc.Syntax.dll as your runtime library for maximum flexibility, along with its dependencies Loyc.Collections.dll and Loyc.Essentials.dll.
- Short learning curve: LLLPG is intuitive to use because it augments an existing programming language and doesn’t attempt to do everything on your behalf. Also, the generated code follows the structure of the input code so you can easily see how the tool behaves.
- Just one parsing model to learn: some other systems use one model (regex) for lexers and something else for parsers. Often lexers have a completely different syntax than parsers, and the lexer can’t handle things like nested comments (lex and yacc are even separate programs!). LLLPG uses just a single model, LL(k); its lexers and parsers have nearly identical syntax and behavior.
- For tricky situations, LLLPG offers zero-width asertions (a.k.a. semantic & syntactic predicates) and “gates”.
- Compared to regexes, LLLPG allows recursive grammars, often reduces repetitions of grammar fragments, and because LLLPG only supports LL(k), it mitigates the risk of regex denial-of-service attacks. On the other hand, LLLPG is less convenient in that grammars tend to be longer than regexes, changing the grammar requires the LLLPG tool to be installed, and writing an LL(k) grammar correctly may require more thought than writing a regex.
- Compared to ANTLR, LLLPG is designed for C# rather than Java, so naturally there’s a Visual Studio plugin, and I don’t sell half of the documentation as a book. Syntax is comparable to ANTLR, but superficially different because unlike ANTLR rules, LLLPG rules resemble function declarations. Also, I recently tried ANTLR 4 and I was shocked at how inefficient the output code appears to be.
- Supports all the features of LeMP.
“Blah, blah, blah! Show me this thing already!”
Sure! Let’s look at some simple examples.