Avoid tedious coding with LeMP
24 Aug 2015 (updated 10 Dec 2016)Introduction
LeMP is a tool I wrote that transforms a source file by running user-defined code to transform syntax trees into other syntax trees. Code that is designed to transform a file’s syntax is called a “macro”. LeMP has a bunch of macros built in, and I will only cover a few of the most useful ones in this initial article. You can write your own macros too, which is discussed elsewhere.
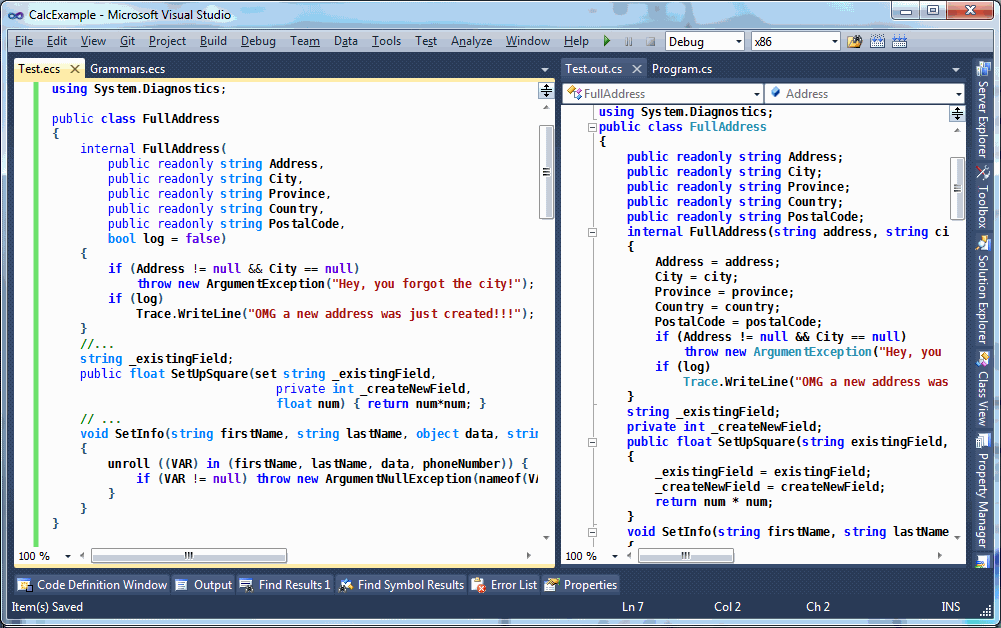
LeMP comes with a Visual Studio Syntax Highlighter (optional), a Visual Studio Custom Tool, command-line tools, and a standalone editor that works on Windows & Linux. All open-source.
This article is a sampling of a few of the things you can do with LeMP.
on_finally
Java introduced the try-finally construct to make sure cleanup happens in case of an exception. This article isn’t designed for beginners, so you should already know that it looks something like this:
{
var obj1 = new Class1();
try {
var obj2 = obj1.MakeAnotherObject();
try {
obj2.DoSomethingElse();
obj1.DoSomethingMore();
} finally {
obj2.Dispose();
}
} finally {
obj1.Dispose();
}
}
Try-finally is a little clumsy to use, so C# introduced the using statement. Code that uses using is not only more compact, it’s also easier to write code correctly with it:
{
using (var obj1 = new Class1())
using (var obj2 = obj1.MakeAnotherObject()) {
obj2.DoSomethingElse();
obj1.DoSomethingMore();
}
}
However, the using statement can only be used if you have some kind of object with a Dispose method. Occasionally you need to do some other cleanup, like restoring a global variable to an old value. In that case, C# still requires you to use try-finally.
It turns out that it’s easier to remember to write cleanup code if you write it first, up front, rather than waiting until the end. LeMP’s on_finally { Cleanup(); } statement allows you to do this. on_finally wraps the rest of the statements in the current braced block in a “try” statement, then adds a finally { Cleanup(); } at the end.
Here’s how the original code above looks like if we use on_finally instead of try-finally:
{
var obj1 = new Class1();
on_finally { obj1.Dispose(); }
var obj2 = obj1.MakeAnotherObject();
on_finally { obj2.Dispose(); }
obj2.DoSomethingElse();
obj1.DoSomethingMore();
}
This code is translated into the original code you saw above. on_finally is perhaps not quite as nice as using, but in situations where cleanup isn’t as simple as calling Dispose(), on_finally is more convenient than using try-finally directly.
Code find-and-replace
C and C++ famously have lexical macros defined with the #define directive. These “macros” are not well-liked for several reasons:
-
Oblivious to structure: C/C++ macros work at the lexical level, basically pasting text. Since they do not understand the underlying language, you can have bugs like this one:
// Input #define SQUARE(x) x * x const int one_hundred = SQUARE(5 + 5) // Output const int one_hundred = 5 + 5 * 5 + 5; // oops, that's 35In contrast, LeMP parses the entire source file, then manipulates the syntax tree. Converting the tree back to C# code is the very last step, and this step will do things like automatically inserting parentheses to prevent this kind of problem.
-
Spooky action at a distance: C/C++ macros have global scope. If you define one inside a function, it continues to exist beyond the end of the function unless you explicitly get rid of it with
#undef. Even worse, header files often define macros, which can sometimes accidentally interfere with the meaning of other header files or source files. In contrast, LeMP macros likedefine(the LeMP equivalent of#define) only affect the current block (between braces). Also, one file cannot affect another file in any way, so many files can be processed concurrently (well, except the Visual Studio plugin can’t). -
Limited ability: there just aren’t that many things you can accomplish with C/C++ macros. With LeMP you can load user-defined macros that can do arbitrary transformations (although it’s outside the scope of this article).
-
Weird language: the C/C++ preprocessor has a different syntax from normal C/C++. In contrast, LeMP code simply looks like some kind of enhanced C#.
So let’s talk about replace and define, the LeMP equivalents of #define.
Replace
replace() {...} is a macro that finds things that match a given pattern and replaces all instances of the pattern with some other pattern. For example,
// Input
replace (MB => MessageBox.Show,
FMT($fmt, $arg) => string.Format($fmt, $arg))
{
MB(FMT("Hi, I'm {0}...", name));
MB(FMT("I am {0} years old!", name.Length));
}
// Output of LeMP
MessageBox.Show(string.Format("Hi, I'm {0}...", name));
MessageBox.Show(string.Format("I am {0} years old!", name.Length));
The braces are optional. If the braces are present, replacement occurs only inside the braces; if you end with a semicolon instead of braces, replacement occurs on all remaining statements in the same block.
As you can see, placeholders like $fmt and $arg are used to “capture” expressions, which are then copied to the output. In the example above, $arg captures name inside the first call to FMT, and in the second call, it captures name.Length. Placeholders marked with $ can capture a syntax tree of any size, from a single integer up to an entire class definition.
This example requires FMT to take exactly two arguments called $fmt and $arg, but we could also capture any number of arguments or statements by adding the .. operator as shown here:
FMT($fmt, $(..args)) => string.Format($fmt, $args) // 1 or more arguments
FMT($(..args)) => string.Format($args) // 0 or more arguments
replace is more sophisticated tool than C’s #define directive. Consider this example:
replace ({
foreach ($type $item in $obj.Where($w => $wpred))
$body;
} => {
foreach ($type $w in $obj) {
if ($wpred) {
var $item = $w;
$body;
}
}
})
var numbers = new[] { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
Console.WriteLine("I wanna tell you about my digits!")
foreach (var even in numbers.Where(n => n % 2 == 0))
Console.WriteLine("{0} is even!", even);
foreach (var odd in numbers.Where(n => n % 2 == 1))
Console.WriteLine("{0} is odd!", odd);
Here, replace searches for foreach loops that have a specific form, and replaces them with a more optimized form:
var numbers = new[] {
1, 2, 3, 4, 5, 6, 7, 8, 9
};
Console.WriteLine("I wanna tell you about my digits!")
foreach (var n in numbers) {
if (n % 2 == 0) {
var even = n;
Console.WriteLine("{0} is even!", even);
}
}
foreach (var n in numbers) {
if (n % 2 == 1) {
var odd = n;
Console.WriteLine("{0} is odd!", odd);
}
}
define
define is similar to replace but it looks like you’re defining a method (or an operator). Here is a simple example:
define MakeSquare($T) {
static $T Square($T x) { return x*x; }
}
MakeSquare(int);
MakeSquare(double);
MakeSquare(float);
// Output of LeMP
int Square(int x) {
return x * x;
}
double Square(double x) {
return x * x;
}
float Square(float x) {
return x * x;
}
define is a great way to construct a series of very similar methods, as this example shows. First I define MakeSquare, a macro that takes a single argument. Technically, $T can capture any syntax tree, but for this example to work properly, it must be a type name. MakeSquare uses that argument to generate a method called Square.
You might run into a small problem when you’re doing this: the parser is unaware of what macros exist so it has no idea that MakeSquare is expecting a type name as its argument (define itself is also unaware of this fact, but that’s another story). Because of this, certain types cannot be passed to MakeSquare. Most notably, a nullable type like MakeSquare(int?) will cause a syntax error. Use MakeSquare(Nullable<int>) instead.
Before I give you the second example I’d like to introduce a special macro called concatId:
concatId(Con, sole).WriteLine("Huh?");
// Output of LeMP
Console.WriteLine("Huh?");
concatId combines two identifiers into a single identifier; in this case Con is combined with sole to get Console. This may be useful inside a replace macro for deriving new names from existing names, which is what we will do in this next example:
define SaveAndRestore($var = $newValue) {
replace (TMP => concatId(old, $var));
var TMP = $var;
$var = $newValue;
on_finally { $var = TMP; }
}
string _curTask = "<No task running>";
void DoPizza(IEnumerable<Topping> toppings)
{
SaveAndRestore(_curTask = "Make pizza");
var d = PrepareDough();
FlattenDough(d);
AddToppings(d, toppings);
Bake(d, TimeSpan.FromMinutes(12));
}
// Output of LeMP
string _curTask = "<No task running>";
void DoPizza(IEnumerable<Topping> toppings)
{
var old_curTask = _curTask;
_curTask = "Make pizza";
try {
var d = PrepareDough();
FlattenDough(d);
AddToppings(d, toppings);
Bake(d, TimeSpan.FromMinutes(12));
} finally {
_curTask = old_curTask;
}
}
Here I’ve used both replace and define, nested inside each other. The replace command changes TMP to concatId(old, $var). Later in the code, where it says SaveAndRestore(_curTask = "Make pizza"), the syntax variable $var becomes _curTask, so concatId(old, $var) turns into concatId(old, _curTask) before the replacement actually occurs. So in effect, this example creates a variable called old_curTask to hold the old value of _curTask. Then, on_finally is used to restore the old value of _curTask at the end of the method.
SaveAndRestore requires that its single argument is some kind of assignment expression. If it’s not - for example, if you write
SaveAndRestore(a + b);
you’ll get a warning message that “1 macro(s) saw the input and declined to process it”, and SaveAndRestore(a + b); will appear unchanged in the output.
The define macro can also match operators. For example
[Passive]
replace operator=(Foo[$index], $value) {
Foo.SetAt($index, $value);
}
x = Foo[y] = z;
// Output of LeMP
x = Foo.SetAt(y, z);
This example has a couple of interesting elements. First, notice that the first parameter of this “operator” is Foo[$index]. This means that the macro has no effect unless the left-hand side of = matches Foo[$index]. For example, Bar[index] would not match this pattern, but Foo[x + y] would. Another intersting thing is the [Passive] attribute. This tells the macro processor not to print a warning when an = operator is found that does not match the pattern. In the code afterward there are two usages of the = operator (the outer one, x = (Foo[y] = z), and the inner one, Foo[y] = z). Only the inner one matches and is replaced.
Technically, the define macro is more than stylistically different from the replace macro described above. replace directly performs a search-and-replace of the code that follows it. On the other hand, define actually creates a new macro by the specified name, which allows any replacements it performs to happen later on, interleaved with other macro evaluations. However, this fact doesn’t make a difference in most cases.
Real-world use case: INotifyPropertyChanged
Some developers have to implement the INotifyPropertyChanged interface a lot. Implementing this interface often involves a lot of boilerplate and code duplication, and it’s easy to make mistakes as you copy, paste and modify your properties. Using normal C#, you can avoid some code duplication by sharing common code in a common method, like this:
public class DemoCustomer : INotifyPropertyChanged
{
public event PropertyChangedEventHandler PropertyChanged;
/// Common code shared between all the properties
protected bool ChangeProperty<T>(ref T field, T newValue,
string propertyName, IEqualityComparer<T> comparer = null)
{
comparer = comparer ?? EqualityComparer<T>.Default;
if (field == null ? newValue != null : !field.Equals(newValue))
{
field = newValue;
if (PropertyChanged != null)
PropertyChanged(this, new PropertyChangedEventArgs(propertyName));
return true;
}
return false;
}
private string _customerName = "";
public string CustomerName
{
get { return _customerName; }
set { ChangeProperty(ref _customerName, value, "CustomerName"); }
}
private object _additionalData = null;
public object AdditionalData
{
get { return _additionalData; }
set { ChangeProperty(ref _additionalData, value, "AdditionalData"); }
}
private string _companyName = "";
public string CompanyName
{
get { return _companyName; }
set { ChangeProperty(ref _companyName, value, "CompanyName"); }
}
private string _phoneNumber = "";
public string PhoneNumber
{
get { return _phoneNumber; }
set { ChangeProperty(ref _customerName, value, "PhoneNumber"); }
}
}
That’s not too bad, but you may need to repeat the ChangeProperty method in multiple classes, and there is still some code duplication, and thus, opportunities to make mistakes (did you notice the mistake in the code above?)
Here’s how you can factor out the common stuff into a replace macro:
replace ImplementNotifyPropertyChanged({ $(..properties); })
{
// ***
// *** Generated by ImplementNotifyPropertyChanged
// ***
public event PropertyChangedEventHandler PropertyChanged;
protected bool ChangeProperty<T>(ref T field, T newValue,
string propertyName, IEqualityComparer<T> comparer = null)
{
comparer ??= EqualityComparer<T>.Default;
if (field == null ? newValue != null : !field.Equals(newValue))
{
field = newValue;
if (PropertyChanged != null)
PropertyChanged(this, new PropertyChangedEventArgs(propertyName));
return true;
}
return false;
}
// The [$(..attrs)] part of this example is puts all attributes into a list called
// `attrs`. This is important because in EC#/LeMP, modifiers like `public` are
// considered to be attributes. So we need this to preserve `public` in the output.
replace ({
[$(..attrs)] $Type $PropName { get; set; }
} => {
replace (FieldName => concatId(_, $PropName));
private $Type FieldName;
[$(..attrs)] $Type $PropName {
get { return FieldName; }
set { ChangeProperty(ref FieldName, value, nameof($PropName)); }
}
});
$properties;
}
The triply-nested replace commands may seem a little complicated, but you can save it in a separate file, such as ImplementNPC.ecs, and forget about those implementation details. Then you can use it in any of your source files like this:
includeFile("ImplementNPC.ecs");
public class DemoCustomer : INotifyPropertyChanged
{
public DemoCustomer(set string CustomerName) {}
ImplementNotifyPropertyChanged
{
public string CustomerName { get; set; }
public object AdditionalData { get; set; }
public string CompanyName { get; set; }
public string PhoneNumber { get; set; }
}
}
The constructor here uses another LeMP feature: the contextual keyword set on the constructor parameter CustomerName causes that parameter to be assigned to the CustomerName property.
Note: The [$(..attrs)] part of this example requires LeMP version 2.3.0 or higher.
unroll & notnull
unroll..in is a kind of compile-time foreach loop. It generates several copies of a piece of code, replacing one or more identifiers each time. Unlike replace, unroll can only match simple identifiers on the left side of in.
/// Input
void ProcessInfo(string firstName, string lastName, object data, string phoneNumber)
{
unroll ((VAR) in (firstName, lastName, data, phoneNumber)) {
if (VAR != null) throw new ArgumentNullException(stringify(VAR));
}
implementation here;
}
/// Output
void ProcessInfo(string firstName, string lastName, object data, string phoneNumber)
{
if (firstName != null)
throw new ArgumentNullException("firstName");
if (lastName != null)
throw new ArgumentNullException("lastName");
if (data != null)
throw new ArgumentNullException("data");
if (phoneNumber != null)
throw new ArgumentNullException("phoneNumber");
implementation here;
}
This example also used the stringify() macro to convert each variable name to a string.
However you could also just use the notnull attribute to get a similar effect, albeit with a different exception type:
void SetInfo(notnull string firstName, notnull string lastName, notnull object data, notnull string phoneNumber)
{
implementation here;
}
// Output of LeMP
void SetInfo(string firstName, string lastName, object data, string phoneNumber)
{
Contract.Assert(firstName != null, "Precondition failed: firstName != null");
Contract.Assert(lastName != null, "Precondition failed: lastName != null");
Contract.Assert(data != null, "Precondition failed: data != null");
Contract.Assert(phoneNumber != null, "Precondition failed: phoneNumber != null");
implementation here;
}
Automagic field generation
I don’t know about you, but I write a lot of “simple” classes and structs, particularly the kind known as “plain-old data” or POD, meaning, little groups of fields like this:
public class FullAddress
{
public readonly string Address;
public readonly string City;
public readonly string Province;
public readonly string Country;
public readonly string PostalCode;
internal FullAddress(string address, string city,
string province, string country,
string postalCode, bool log = false)
{
Address = address;
City = city;
Province = province;
Country = country;
PostalCode = postalCode;
if (Address != null && City == null)
throw new ArgumentException("Hey, you forgot the city!");
if (log)
Trace.WriteLine("OMG a new address was just created!!!");
}
...
}
You don’t have to write classes like this very many times before you start to get annoyed at having to repeat the same information over and over: each of “address”, “city”, “province”, “country” and “postalCode” are repeated four times with varying case, “string” is repeated ten times, and “FullAddress” is repeated twice (three times if you add a default constructor).
With LeMP and Enhanced C# you get the same effect with much shorter code:
public class FullAddress {
internal this(
public readonly string Address,
public readonly string City,
public readonly string Province,
public readonly string Country,
public readonly string PostalCode,
bool log = false)
{
if (Address != null && City == null)
throw new ArgumentException("Hey, you forgot the city!");
if (log)
Trace.WriteLine("OMG a new address was just created!!!");
}
...
}
As explained on the home page, this code generates virtually identical output to the original class above.
A feature similar to this was being considered for C# 6, called “primary constructors”. They looked like this:
struct Pair<T>(T first, T second)
{
public T First { get; } = first;
public T Second { get; } = second;
...
}
But primary constructors were limited:
- You couldn’t easily validate the constructor parameters, as I have done in
FullAddress. - You couldn’t take an action that wasn’t related to assigning a constructor parameter to a field or property, as I have done with
log. - The constructor was forced to be
public(FullAddresshas aninternalconstructor).
In contrast, the feature I’m showing you actually has nothing to do with constructors. True story, when I first wrote the unit tests for this feature, I forgot to test it on constructors… so naturally, it didn’t work on constructors.
This macro, also known as SetOrCreateMember, will work on any method, and you can use the set attribute to merely change a field instead of creating a field:
/// Input
string _existingField;
public float Example(set string _existingField,
private int _createNewField,
float num) { return num*num; }
/// Output
string _existingField;
private int _createNewField;
public float Example(string existingField, int createNewField, float num)
{
_existingField = existingField;
_createNewField = createNewField;
return num * num;
}
Installing LeMP
If you like this tool, you’ll want to run it, so follow the installation instructions. If you’d like to run it on Linux, LeMP also has a built-in editor (e.g. run mono LeMP.exe --editor)
To use the custom tool,
- create a C# file, and optionally write some code in it (sometimes I write quite a lot of code at this point, because IntelliSense disappears in the next step).
- In the Solution Explorer, change the extension of the new file to .ecs
- Right-click your .ecs file in Solution Explorer and click Properties
- In the Properties panel, change the Custom Tool field to “LeMP” (it’s not case sensitive). An output file should appear with an extension of
.out.cs.
By the way, if you’d like me to write an article about how to write VS syntax highlighters, I can do that too… I already wrote one for Single file generators, after all…
Introducing LLLPG
There’s one more macro I’ll mention, and it’s huge - literally, it comes in its own 353 KB assembly.
It’s called LLLPG, the Loyc LL(k) Parser Generator, and it generates parsers and lexers from LL(k) grammars.
Introducing Enhanced C#
Enhanced C# is normal C# with a bunch of extra syntax. This actually has nothing to do with LeMP, aside from the fact that a lot of the new syntax exists simply to allow macros to make use of it. Unlike some other macro systems, LeMP and EC# do not allow macros to define new syntax. EC# is a “fixed-function” parser, not a programmable one.
A few bits of this syntax have been used in the article already:
- The
$and..operators, which are used for capturing syntax trees as you have seen. - Word attributes: I observed that normal C# has something called “contextual keywords” like
yieldandpartialthat are normally not keywords, unless used in a specific context. I generalized this idea by allowing my parser to treat any identifier as a contextual keyword. Thussetis a contextual keyword inset string _existingFieldandruleis a contextual keyword inpublic static rule int ParseInt(string input). - Macro blocks: there is a new statement of the form
identifier (args) {statements;}. It is used to invoke macros, although there are also many macros that don’t use this syntax. Macro blocks can also have the simpler formidentifier {statements;}. Property getters and setters likeget {...}andset {...}are actually parsed using this rule. - Methods as binary operators: given a method like
Add(x, y), you are allowed to writex `Add` yinstead. It means the same thing. - Attributes on expressions: words like
public,static,override, andparamsare “attribute keywords” that modify the meaning of whatever comes afterward. In normal C# you can only put these attributes on things like fields, methods, and classes; but enhanced C# allows you to put attributes on any expression, in case a macro might use the attribute. That explains whyConstructor(public readonly int Foo) {}is a valid statement. - Token trees: as I mentioned, EC# is a fixed language with a fixed syntax. However, one of the bits of syntax is called a token tree, which has the form
@{ list of tokens }. A token tree is a collection of tokens with parentheses, brackets and braces grouped together (e.g.@{ ] }is an invalid token tree because the closing bracket isn’t matched with an opening bracket). Long after the file is parsed, the token tree can be reparsed by a macro (e.g. LLLPG) to give meaning to its contents.
EC# includes many other adjustments to the syntax of C#, and they are very nearly 100% backward compatible with standard C#, although the parser may contain bugs and I welcome your bug reports.
You might be wondering, “hey, didn’t you have to do a lot of work to extend the C# parser to support all this extra syntax?” and the answer is: actually, no, not really; I mean it was a lot of work to parse C# from scratch, but in fact the Enhanced C# parser is less complex than the standard one. Last time I checked, Roslyn’s parser was 10,525 lines of code (442 KB), while the EC# parser is about 2500 lines of code (with comparable quantities of comments in both). EC# uses LLLPG, with about 5000 lines of generated output code (137 KB).
How can it be smaller when it has more syntax? Well, LINQ isn’t done yet, so that’s a factor. But in many ways the syntax of EC# is more regular than standard C#; for instance, a method’s formal parameters are essentially just a list of expressions, so this method is parsed successfully:
public void Foo<T>(new T[] { "I don't think this belongs here" }) {}
Effectively, I’ve shifted some of the burden of checking valid input to later stages of the compiler–stages which, incidentally, don’t exist yet. This design has two advantages:
-
The parser is simpler.
-
Macros can take advantage of any strange syntax this allows. For example, remember the replace macro?
replace ($obj.ToString() => (string)$obj) {...}The expression
$obj.ToString() => (string)$objre-uses the lambda operator=>for a new purpose it was never designed for. In order for this to parse successfully, the lambda operator is treated almost identically to other operators like+or=; it merely has a different precedence and enables recognition of unassigned variable declarations on the left-hand side. By not treating=>as a special case, I simultaneously made the parser simpler and added a new form of operator overloading for it (which, to be clear, is completely different than the operator overloading you’re used to - it’s available only to macros).
Everything is an expression
Enhanced C# is built on the concept of a “universal syntax tree” that I call the Loyc tree. Rather than parsing to a syntax tree designed specifically for C#, the EC# parser parses to this more general form. If you want to write your own macros, you may have to deal with Loyc trees, although often you can avoid knowing anything by relying on the quote and matchCode macros, described in the second article.
If you’ve ever programmed in Lisp, you know that there is no separate concept of “statements” and “expressions”: everything is an expression. Arguably the most interesting thing about Enhanced C# is that it’s also an expression-based language. Of course, the parser must make a clear distinction between statements and expressions: X * Y; is a pointer variable declaration, whereas N = (X * Y); is a multiplication. Statements end in semicolons, while expressions, er, don’t.
The following code, for example, relies on the lack of a distinction (in the syntax tree) between statements and expressions:
/// Input
string nums = string.Concat(
unroll(N in (1,2,3,4,5,6,7)) {
stringify(N);
}, " [the end]"
);
/// Output
string x = string.Concat("1", "2", "3", "4", "5", "6", "7", " [the end]");
unroll doesn’t know or care that it’s located in an “expression context” instead of a “statement context”.
When the parser is parsing expressions (e.g. 1,2,3) they are separated by commas, but curly braces normally cause a switch to statement-parsing mode; therefore stringify(N) is followed by a semicolon. The semicolon isn’t part of the syntax tree, it’s merely marks the end of each statement. Then when the unroll macro is done, it deletes itself along with the curly braces, leaving only a list of expressions "1", "2", "3", etc. Because these are printed in a location where expressions, are expected, they are separated by commas and not semicolons.
On the other hand if we simply write
unroll(N in (1,2,3,4,5,6,7)) { nameof(N); }
The output is separated by semicolons:
"1";
"2";
"3";
"4";
"5";
"6";
"7";
This output, of course, isn’t valid C#, but it is a perfectly valid syntax tree. Actually more of a list. Whatever.
Welcome to Bizarro World
This concept of an expression-based language explains some otherwise puzzling things about EC#. For example, if I give EC# the following input:
[#static]
#fn(int, Square, #(#var(int, x)), @`'{}`( #return(x*x) ));
It spits out the following output:
static int Square(int x)
{
return x * x;
}
What the heck happened? No, #fn is not some kind of bizarro preprocessor directive. What you’re looking at is a representation of the syntax tree of a method. #fn means “define a function”.
Don’t be confused by the # sign. It does not mark a preprocessor directive; the EC# parser doesn’t really treat # as a special character - unless you write a preprocessor directive (like #if), # is an identifier character, much like an underscore or a capital K. Although #fn is parsed as an ordinary name, its meaning is special, because it represents a function. By analogy, when you write var s = "", the C# compiler parses var as an ordinary identifier, not a keyword, but it has a special meaning nonetheless. Likewise #fn is parsed like a method call but has a special meaning.
#fn takes four arguments: the return type (int), the method name (Square), the argument list (#(#var(int, x)) is a list containing a single item; #var(int, x) declares a variable called x), and the method body. It can also have an unlimited number of attributes. The rarely-used notation @`'{}` is an identifier named "'{}" that is being “called” with one parameter, the #return statement. Of course, the braces themselves are not a function, and when I say @`'{}` is being “called”, I simply mean that subexpressions are being associated with an identifier named “’{}”. These subexpressions are said to be the “arguments” of @`'{}`.
Why do functions and braces look like function calls? Because Loyc trees do not have a concept of functions and braces, only “calls”. Thus, ordinary function calls and other constructs like functions, properties and classes are all represented in a similar way, with “calls”. This makes Loyc trees very simple; they were inspired by the simplicity of Lisp, although Loyc trees are significantly more complex than Lisp s-expressions.
There’s something called an “EC# node printer” whose job is to print C# code. When it sees a tree like
@#fn(#of(@`'?`, double), Sqrt, #(#var(double, x)),
{ return x < 0 ? null : Math.Sqrt(x); }
);
It recognizes this as a perfectly normal syntax tree for a function declaration, so it prints
double? Sqrt(double x)
{
return x < 0 ? null : Math.Sqrt(x);
}
As you can see, you can freely mix “prefix notation” like #var(double, x) with ordinary notation like Math.Sqrt(x). It is strongly recommended not to use constructs like #fn or #var directly, because the underlying syntax tree for a method or variable declaration is not guaranteed not to change in the future.
The nice thing about representing programming languages with a “Loyc tree” is that it provides a starting point for converting code between programming languages. In theory one could define some kind of “Standard Imperative Language” as an intermediate representation, a go-between that would help convert any source language to any target language.
The other nice thing about Loyc trees is that LeMP can operate on any Loyc tree, it doesn’t matter what programming language it came from. Currently LeMP only works on two languages, EC# and a small language I designed called Loyc Expression Syntax (LES), but someday I hope it will support other languages like Java, ES6, Python, or whatever the community is willing to write parsers and printers for.
You might find it fun to go in the reverse direction and see what kind of syntax tree your ordinary C# code is parsed as. Just write some normal C# code in your .ecs file:
using System.Collections.Generic;
class MyList<T> : IList<T> {
int _count;
public int Count {
get { return this._count; }
}
}
Then change the Visual Studio Custom Tool to “LeMP_les” to see the output as an LES syntax tree:
#import(System.Collections.Generic);
#class(MyList `#of` T, #(IList `#of` T), {
#var(#int32, _count);
@[#public] #property(#int32, Count, @``, {
get({ #return(#this._count); });
});
});
Okay, that’s enough bizzaro world for one day.
Conclusion
Final thought: if you could add features to C#, what would they be? If there’s a way to treat that feature as a purely syntactic transformation (“syntactic sugar”), chances are good there’s some way to accomplish it with LeMP.
You can post comments on the old version of this article originally published on CodeProject.
To learn about more of the macros available, please visit the home page. If you’re puzzled about how to accomplish something with LeMP, maybe I can help - just ask!